1.input task format(任务输入配置)初识
注:本节介绍以YAML格式配置任务输入为例进行介绍,JSON格式类似
可以将input task format理解成测试执行前的准备动作。除了资源的准备,还包括了测试的评估指标设置(sla)。
下面介绍一个简单的场景测试。具体查看
https://github.com/openstack/rally/tree/master/samples/tasks/scenarios/keystone/create-and-get-role.yaml
内容如下所示:
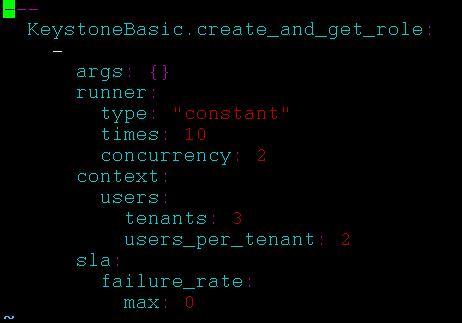 这就是一个标准的rally场景测试任务输入配置。
rally的任务输入配置(input task format)如下所示:
这就是一个标准的rally场景测试任务输入配置。
rally的任务输入配置(input task format)如下所示:
taskname:
benchmark_config1
benchmark_config2
而benchmark_config格式如下所示:
args:
runner:
context:
sla:
在benchmark_config配置中:
args:运行一个benchmark测试时需要传入的参数;
runner:配置runner的类型以及runner的配置参数;
context:配置执行benchmark测试时的应用上下文(主要有用户、网络等);
sla:Service-Level Agreement(服务等级协议),也被理解为Success critera,表示供应商对客户的性能承诺;
下面看一下复杂点的task任务输入配置,如下图所示:
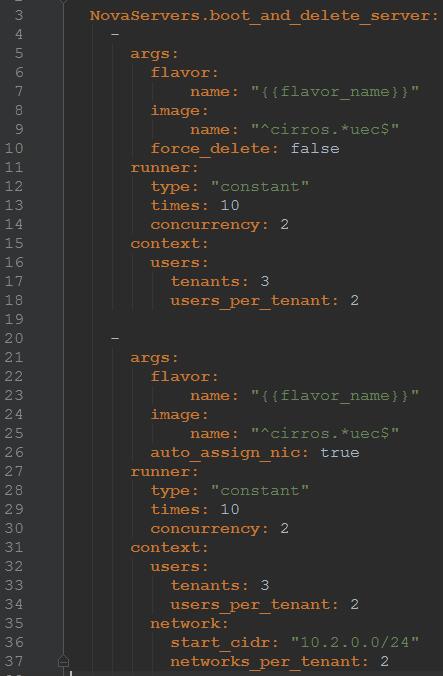 在该rally任务输入配置中,有两个benchmark测试,在benchmark测试中的args中配置了flavor,image等信息;runner中指定了type(运行者类型)、time(测试次数)、concurrency(并发量);在context中指定了users相关信息。
rally测试与tempest测试的一个最大不同点在于:sla的引入。
我们可以将sla理解为商家对客户性能的承诺。举例来说:客户要求云供应商提供的解决方案中每10次创虚拟机动作中时间超过1分钟的次数小于5次,如果供应商对交付的云服务使用rally测试创虚拟机操作,如果达到了这一要求则可任务供应商是通过sla标准,反之则没有达到。
再看一个rally中的一个配置了sla标准的场景测试(KeystoneBasic.create_delete_user),如下图所示:
在该rally任务输入配置中,有两个benchmark测试,在benchmark测试中的args中配置了flavor,image等信息;runner中指定了type(运行者类型)、time(测试次数)、concurrency(并发量);在context中指定了users相关信息。
rally测试与tempest测试的一个最大不同点在于:sla的引入。
我们可以将sla理解为商家对客户性能的承诺。举例来说:客户要求云供应商提供的解决方案中每10次创虚拟机动作中时间超过1分钟的次数小于5次,如果供应商对交付的云服务使用rally测试创虚拟机操作,如果达到了这一要求则可任务供应商是通过sla标准,反之则没有达到。
再看一个rally中的一个配置了sla标准的场景测试(KeystoneBasic.create_delete_user),如下图所示:
 在该配置任务配置输入中,sla标准配置了最大迭代时间(max_seconds_per_iteration)为4s,失败率不能超(failure)过1%,平均迭代时间(max_avg_duration)不能超过3s。除此之外,为了防止异常点(outliers)的出现,此处还配置了异常点的评判标准。sla的代码实现不进行详细说明,具体实现请参考
在该配置任务配置输入中,sla标准配置了最大迭代时间(max_seconds_per_iteration)为4s,失败率不能超(failure)过1%,平均迭代时间(max_avg_duration)不能超过3s。除此之外,为了防止异常点(outliers)的出现,此处还配置了异常点的评判标准。sla的代码实现不进行详细说明,具体实现请参考https://github.com/openstack/rally/tree/master/rally/plugins/common/sla。
2.Rally Task核心设计
2.1 Task执行时的顺序图
当我们调用rally task start xxxx.yaml时,rally中到底执行的流程是什么呢?如下图所示。当我们执行rally task start xxxx.yaml时,最先触发的是TaskCommands,该类用于解析Task相关命令,并触发后面的工作流程。TaskEngine是最核心的类之一,其负责获得相关的Context、workload(xxxx.yaml的解析结果类)和ScenarioRunner,并调用ScenarioRunner执行Task。 
2.2 Task相关核心类图
在执行Task时,如果在Input task configure中没有配置users信息,则RoleGenerator和UserGenerator会生成相关user和role。 
2.3 Task核心并发测试设计
在介绍此小节时回顾前文中runner的配置主要有三个配置组成。
runner:
type:指定runner的类型(constant、rps、serial、constant_for_duration)
time:迭代执行次数
concurrency:每一次迭代中并行的线程数
本节将介绍time和concurrency在rally中的代码设计。 在/rally/rally/task/engine.py中触发TaskEngine.run()函数时,进入runner的核心代码如下所示:
with ResultConsumer(key, self.task, runner_obj,
self.abort_on_sla_failure):
with context.ContextManager(context_obj):
runner_obj.run(workload.name, context_obj,workload.args)
runner_obj即为runner对象,runner_obj.run()时即触发了多线程worker来进行并发的测试。
 在上图中,我们可以看见ScenarioRunner有两个函数方法:run()以及_run_scenario()函数。其中_run_scenario()是抽象函数,需要各个子类Runner去实现。当我们触发**runner_obj.run()**时,最终调用的是子类的_run_scenario()函数(软件设计工程中遵循的“对修改封闭,对扩展开放原则”)。
在上图中,我们可以看见ScenarioRunner有两个函数方法:run()以及_run_scenario()函数。其中_run_scenario()是抽象函数,需要各个子类Runner去实现。当我们触发**runner_obj.run()**时,最终调用的是子类的_run_scenario()函数(软件设计工程中遵循的“对修改封闭,对扩展开放原则”)。